Through the lens of Filipino workers
A data science project that delves into the issue of labor struggles in the Philippines through exploratory analysis and natural language processing (NLP) of data sourced from the subreddit r/AntiworkPH.
Everyone needs a source of income to live comfortably;
for most Filipinos—it's more than just about making ends meet
In December 2023, the Philippines logged an unemployment rate of 3.1%, a decrease of 617,000 unemployed individuals from the previous year[1]. This improvement is being celebrated as the lowest unemployment rate in almost two decades, but beyond these statistics, the country is continuously plagued by pressing labor issues.
As of 2024, the current minimum wage is set at ₱573-₱610 in Metro Manila, the highest in any other region. In comparison, the required minimum to feed a family of five is ₱1188 per day according to the IBON foundation[2].
With such low wages, some choose to be separated from families and face poor job conditions to pursue employment outside the country, as the number of Overseas Filipino Workers reaches its peak in 55 years[3]. That is not to say that local workers lack in their share of labor exploitation. Contractualization, a common employment practice in the country that hires workers for short-term contracts, leaves affected Filipinos without necessary benefits and job security.
Under the 17 Sustainable Development Goals (SDG) established by the United Nations General Assembly, specifically SDG 8, there; is a need to “protect labor rights and promote safe and secure working environments for all workers, including migrant workers, in particular women migrants, and those in precarious employment.” For the country to achieve this goal, the issues faced by the Philippine workforce must first be properly recognized and addressed before eventually focusing on resolving them.
There's so much data on the Internet, and here's what we can do
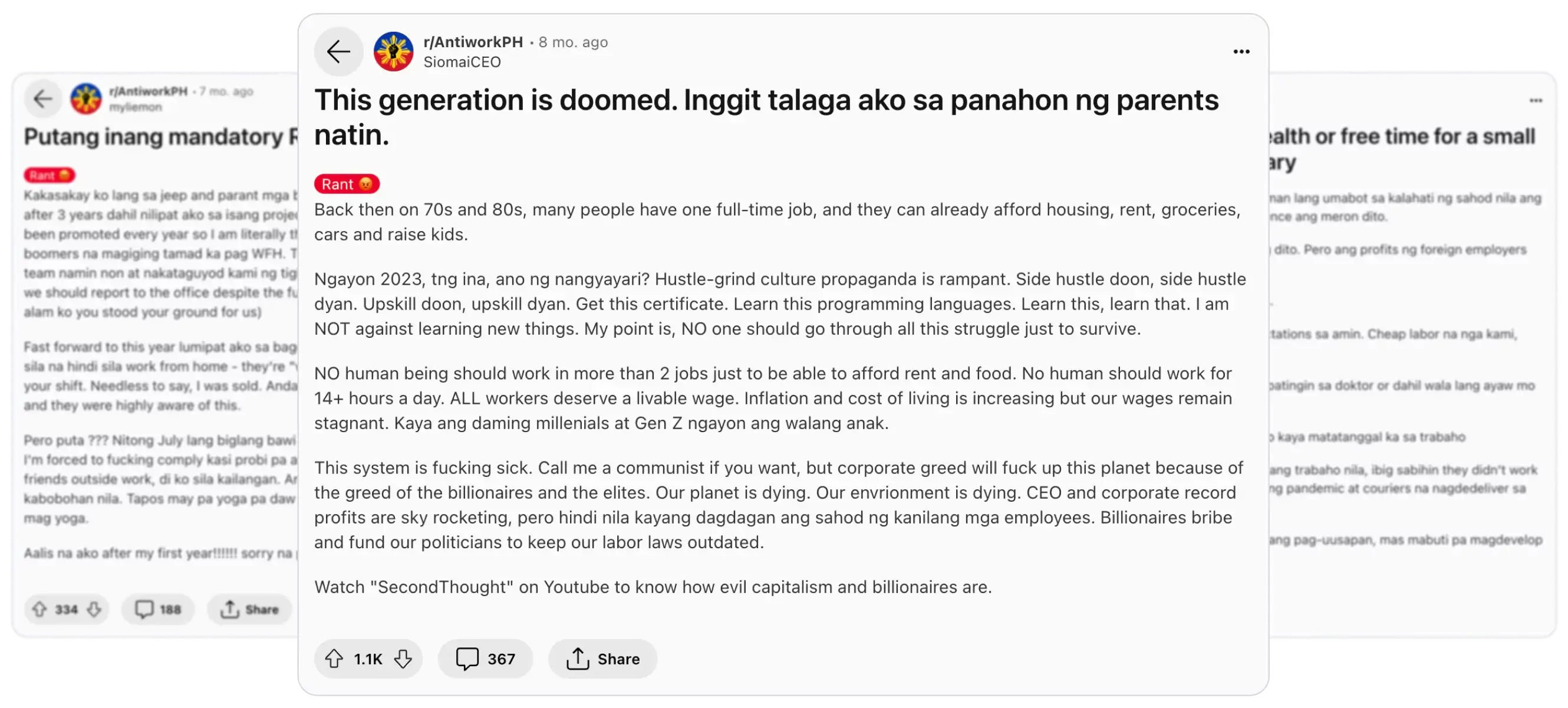
The subreddit r/AntiworkPH provides workers a platform to vent their frustrations and, consequently, shed light on the current situation of the Philippine labor market.
As such, we seek to unravel which topics have plagued the Philippine workforce since the subreddit started on 2022. Through this, our group aims to bring awareness and hopefully provide a more realistic view of the Philippine labor environment.
Then—what are the prevalent topics about labor struggles submitted on r/AntiworkPH?
Null Hypothesis
The prevalent topics among the subreddit users centered around unfair contracts and job offerings in the Philippines.
Alternative Hypothesis
The prevalent topics among the subreddit users did not center around unfair contracts and job offerings in the Philippines.
Which of these topics receive the most Reddit engagements?
Null Hypothesis
The topic with the most engagements based on upvotes and comments is the same as the most prevalent topic.
Alternative Hypothesis
The topic with the most engagements based on upvotes and comments is different from the most prevalent topic.
What now?

Collect various submissions on r/AntiworkPH using a Reddit API.

Extract relevant topics using natural language processing.

Analyze the relationships of these topics to various Reddit metadata.
'/%3e%3cg%20filter='url(%23filter0_d_403_11)'%3e%3ccircle%20cx='249.75'%20cy='7.75'%20r='2.75'%20fill='%23FF6C16'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_d_403_11'%20x='242.7'%20y='0.7'%20width='14.1'%20height='14.1'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeColorMatrix%20in='SourceAlpha'%20type='matrix'%20values='0%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%200%20127%200'%20result='hardAlpha'/%3e%3cfeOffset/%3e%3cfeGaussianBlur%20stdDeviation='2.15'/%3e%3cfeComposite%20in2='hardAlpha'%20operator='out'/%3e%3cfeColorMatrix%20type='matrix'%20values='0%200%200%200%201%200%200%200%200%200.368627%200%200%200%200%200.00392157%200%200%200%201%200'/%3e%3cfeBlend%20mode='normal'%20in2='BackgroundImageFix'%20result='effect1_dropShadow_403_11'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='effect1_dropShadow_403_11'%20result='shape'/%3e%3c/filter%3e%3cradialGradient%20id='paint0_radial_403_11'%20cx='0'%20cy='0'%20r='1'%20gradientUnits='userSpaceOnUse'%20gradientTransform='translate(250%207.75)%20scale(250%2065.5065)'%3e%3cstop%20stop-color='%23FF5E01'%20stop-opacity='0.5'/%3e%3cstop%20offset='0.53'%20stop-color='%23E5E5E5'/%3e%3cstop%20offset='1'%20stop-color='%23E5E5E5'%20stop-opacity='0'/%3e%3c/radialGradient%3e%3c/defs%3e%3c/svg%3e)
PART I
Data Collection
Describing the Data
We want to gather the data we need using Python Reddit API Wrapper (PRAW). According to its documentation, we can access any subreddit, its list of submissions, and useful metadata for each submission. For this project, we specifically gathered the following metadata:
String:
Timestamp
Content Type (text, video, image)
Title
Content (caption if media)
Flair
Submission ID
Integer:
Upvotes Count
Comments Count
Float:
Upvote:downvote Ratio
We kept track of the submission content type so that we may manually extract their transcripts.
Scraping the Data: Limitations
In using PRAW, there are a couple of limitations to note:
1.
Mining Limit – PRAW only allows us to collect up to 1000 submissions for each request. This means that we don't have much control on the data we get as it will always return relatively the same 1000, implying that we can't consistently scrape unique submissions per request.
2.
No Time Customizations – We can't filter submissions based on specfic posting times and time intervals. This is quite unfortunate as it would be difficult to minimize the time bias.
Scraping the Data: The Gameplan
Now, here's the plan:
1.
To sample the subreddit, we want to scrape 1000 submissions per category. The categories are: Hot, New, Rising, Controversial, and Top. Upon scraping, we found out that Rising is a subset of Hot, and hence would left us with Hot, Top, New, and Controversial. For Top, we picked All Time as it would give us submissions older than last year, i.e. April 2023.
•
We opted not to use the search function since one of the objectives of our project is to find those relevant keywords themselves.
•
We also opted not to scrape the comments as they are naturally highly contextualized to the main post. Text with little to no context may only cause the model to overfit.
•
Note that due to the mining limitation, we are not able to fully reach 1000 submissions per category as submissions are not unique to one category.
2.
To avoid duplicates, we want to use the Save function and mark the submission we've already scraped.
3.
To save time, we want to skip non-text-only submissions that have less than 10 upvotes since transcribing them may be counterproductive.
4.
Then as much as possible, we need to minimize time bias. Hence, we won't scrape submissions that are 10 days old or younger as they may have yet to peak in engagements.
Executing the gameplan gave us...
2541 scraped submissions
But now comes the hard part—cleaning the data.
Cleaning the Data
1.
Using Pandas, RegEx, and BeautifulSoup4 on Jupyter Notebook, we want to:
•
Remove URLs, duplicates, emojis, and submissions with empty cells except Content (to be transcribed later on) and Flair .
•
Convert Content to plaintext as it is retrieved as markdown. This also includes replacing newlines and NaNs with a single whitespace.
•
Contextualize Filipino slangs, text abbreviations, and corporate jargons such as converting "WFH" to "Work from home" or "Charot" to "Just kidding". However, it is to note that we can only cater a handful list of them (available on the GitHub repository). This would also raise the possibility of incorrectly defining an acronym, but doing this may be more beneficial as it heavily contextualizes the text.
•
Concatenate Title and Content of every submission into one cell under a new column Title+Content .
•
Add another column that converts Timestamp into a Unix Timestamp (the number of seconds that have elapsed since January 1, 1970) for ease when we do a timeseries later on. Only the day, month, and year are converted for the plot.
2.
Using spaCy's English transformer pipline en_core_web_trf and its power to recognize named entities, we remove the names in the dataset to avoid possible doxxing.
3.
We then want to manually transcribe the image and video content. We shortlist the 100 most engaged submissions from each category to save time as effort to value ratio may be low.
4.
Translate Title+Content to English using the Google Translator of deep_translator API.
5.
Lastly, remove punctuations, numbers, and stop words of Title+Content then convert it to lowercase using Natural Language Toolkit (NLTK) and Pandas. We chose not to lemmatize the words as we plan to identify topics through clouds of words (which we will see later on) where we want to keep the context as much as possible.
We then finally get...
1976 preprocessed submissions!
Considering the subreddit was just made in 2022, what's the distribution like?
Distribution of data per year
PART II
Data Exploration
Now that our data has been processed, the next step would be to solve the research questions posed at the start of the study. To do this, we would need to focus on how to define and identify submissions, a.k.a. posts, on unfair contracts and job offerings as hypothesized.
Manual Topic Tagging
Through manual tagging, we categorized the submissions into two topics: unfair contracts and job offerings and its complement. For ease, we refer to the former as Unfair and to the latter as Non-Unfair.
Each of the posts were searched for keywords that indicated discussions on job offerings and contracts, and if they were unfair or not.
For example, in labelling posts about job offers, we performed a simple search for the keywords “job” and “offer/offers/offering/offerings” to denote job offerings and "contract/s" to denote contracts, and checked if they exist in each submission. The filtered submissions were then filtered again by checking if they contain the words “unfair” or “unjust”, which would tag them as Unfair.
For the remaining posts that don't contain the words "unfair" or "unjust", manual checking was done to determine if the context of the submission was indeed unfair. The submissions are tagged as Unfair if they are either about unfair contracts or unfair job offerings.
LDA Topic Modeling
To further the investigation, we used Latent Dirichlet Allocation (LDA) topic modeling that categorizes the submissions into n topics through Bayesian probability. LDA is an unsupervised machine learning algorithm and will be expounded more in the next section! We've only introduced it as early as now so we can appreciate how it expands our findings.
To do that, we first tokenized the submissions to 1-gram tokens with at least length of 3 characters. Then, we used term frequency-inverse document frequency (TF-IDF) to vectorize (ie. turn them into meaningful numbers) the tokens. Using TF-IDF reveals the relevance of tokens via frequency which will be quite helpful in topic modeling. The code for this process is also included in the given GitHub repository above.
After numerous attempts in using LDA, we settled for 5 topics as it returned very sensible, if not the most, tokens that can be categorized into topics with little to no intersection. It is then to note that LDA only gives a list of words, and it's up to us how we would interpret and name the topic.
Here are the 5 topics LDA has extracted with their corresponding word cloud to visualize their most common words:

The first topic's word cloud contain words relating to termination of employment, such as resignation, clearance, and contract. We can also see that the term 'coe' is here which most likely stands for Certificate of Employment that is usually given to leaving employees. As such, the topic can be labeled as relating to the employee exit process.

Notice that we can assemble the words into more meaningful ones such as business process outsourcing (BPO) and minimum wage. Other keywords include culture, Christmas, party and people. This topic can be labeled to be about BPO work and culture.

In this topic, the keywords seem to reflect important terms used in job applications like interview, offer, applied, experience. As such, the topic represents can be concluded as job application.

For this one, the words boss and coworker, task, report, and performance are explored. Moreover, adjectives such as angry, good, wrong, bad were mentioned. It can be gleaned that this topic represents posts regarding workplace management.
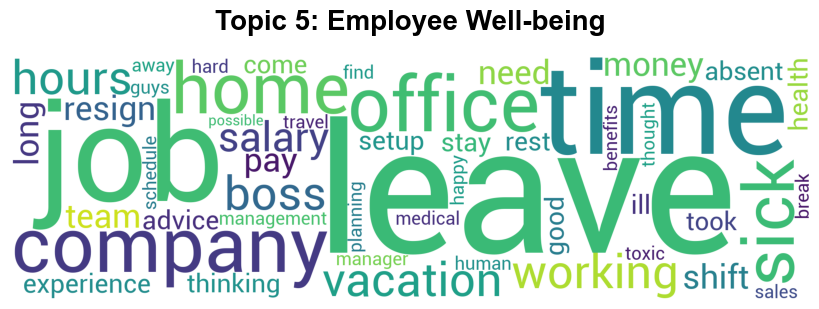
Main keywords for this topic are related to time-off from work and employee benefits. Coupled with positive indicators like happy, good, health, this appears to represent posts related to employee well-being.
Research Question #1
What are the prevalent topics about labor struggles submitted on r/AntiworkPH?
Exploratory Data Analysis
With such a large dataset, a picture may be hidden and left unseen without proper visualization. To delve deeper into the problem, we performed further analysis by constructing graphs to visualize the data better.
For the first research question, two sets of plots* were prepared to identify the prevalence of topics in the subreddit of interest by examining the monthly and cumulative frequency of posts through time.
*The following plots are interactive so feel free to hover and play around!
Manually-tagged Topics
Figure 1. Monthly frequency of Unfair and Non-Unfair.
Figure 2. Cumulative frequency of Unfair and Non-Unfair.
Posts labeled as Non-Unfair were consistently prevalent over posts labeled as seen in Figures 1 and 2. Both plots showed that the rate at which Unfair were posted was fairly consistent. On the other hand, the inverse topic spiked on Jun 2023 and Feb 2024, after a sharp increase starting from Dec 2023.
Upon further research, there was a significant decrease in the Philippine employment rate from 96.9% in Dec 2023 to 95.5% in Jan 2024, as reported by PSA this May 2024. Notably, the spike in June 2023 is incidental to the timing of recent college graduates entering the Philippine Job Market, which may be a possible cause for the spike. Consequently, there are dips occurring in the Monthly Frequency plot every March. This may be due to said college graduates focusing on their final requirements due to graduation being near.
LDA Topics
Figure 3. Monthly frequency of LDA Topics.
Figure 4. Cumulative frequency of LDA Topics.
Meanwhile, as seen in Figures 3 and 4, the LDA plots showed that the BPO Work & Culture topic was mostly consistent in terms of having the most number of posts, with the Monthly Frequency plot indicating a spike in posts in June 2023.
This may suggest an event happening in the BPO industry during this time, as supplemented by the same PSA report that employment rate from May 2023 to July 2023 was noted with the aforementioned decrease. This could imply that several people were frustrated with the BPO work culture and/or faulty work management, as evidenced by the slight spike in the Workplace Management topic.
By December 2023, all topics had a sharp spike in their number of posts, with the Employee Exit Process topic taking the top spot. This peak may give insight as to why there was a spike in the Manual plot earlier, as supplemented by the decreased employment rate in the period mentioned in the previously referenced report.
Recalling our hypothesis...
Null Hypothesis
The prevalent topics among the subreddit users centered around unfair contracts and job offerings in the Philippines.
Alternative Hypothesis
The prevalent topics among the subreddit users did not center around unfair contracts and job offerings in the Philippines.
Hypothesis Testing
To test our hypothesis for the first research question, we used the Chi-Square Goodness of Fit to test if the frequency distribution of the manually-tagged topics is significantly different from the expected.
The contingency table can be seen in Table 1 below. The observed values were calculated on Python by taking the number of submissions under Unfair, and subtracting that value from the total number of posts for the Non-Unfair column. The expected values were each set to half the total number of posts since our goal is simply to get the distribution of each category.
| Unfair | Non-Unfair | |
| Observed no. of Posts | 166 | 1810 |
| Expected no. of Posts | 988 | 988 |
Table 1. Contingency table of manually-tagged topics on their frequency.
For a test of significance at α = 0.05 and df = 0.05, we get X2 = 1367.7814 and p-value = 2.1070e-299. As such, since we have a p-value less than our significance level, we therefore reject the null hypothesis, believing that the prevalent topic in the subreddit is not centered around unfair contracts and job offers.
Research Question #2
Which of these topics receive the most Reddit engagements?
Exploratory Data Analysis
Similar to how the first research question was tackled, we also performed further analysis by constructing graphs. This time, however, engagement was used as a metric over the frequency of posts to address the second research question. Engagement was calculated by summing the number of upvotes and comments, then multiplying them to the upvote:downvote ratio that acts as the weight.
The two sets of plots prepared to examine the performance of posts by the number of engagements were measured in terms of monthly and cumulative values through time. As with the previous plots, the first set used data manually tagged on mentions of unfair job offerings and contracts while the second set makes use of the five topics identified by the LDA.
Manually-tagged Topics
Figure 5. Monthly engagement of Unfair and Non-Unfair.
Figure 6. Cumulative engagement of Unfair and Non-Unfair.
Looking at Figures 5 and 6, Posts tagged as not about Unfair Offerings consistently received more engagements, with significant spikes in June 2023 and Dec 2023 which line up with our analysis earlier.
LDA Topics
Figure 7. Monthly engagement of LDA Topics.
Figure 8. Cumulative engagement of LDA Topics.
The topic BPO Work & Culture had the most engagement with a significant spike in June 2023, which coincides with the topic's amount of posts for the same month, as seen in Figure 7.
However, the topic's engagement started declining by Dec 2023, with the Employee Well-being topic taking its place. This may suggest that the sharp employment rate decline took a toll on employee well-being or, at the very least, is related to it.
Recalling our hypothesis...
Null Hypothesis
The topic with the most engagements based on upvotes and comments is the same as the most prevalent topic.
Alternative Hypothesis
The topic with the most engagements based on upvotes and comments is different from the most prevalent topic.
Hypothesis Testing
Moving on to the testing of the hypothesis for the second research question, we used the same statistical tool. However, the topic of unfairness of job offers and contracts is now tested with the engagements of posts in the subreddit.
The contingency table is seen in Table 2. The observed values were calculated on Python by taking the summed engagement of submissions under Unfair, and subtracting that value from the total number of posts for the Non-Unfair. These values were then divided by the total number of posts per category as recorded earlier (166 for Unfair, 1810 for Non-Unfair) to get the final values. The total engagements were then taken by adding the engagements by all posts and dividing that value by the number of posts. This value was then halved to get the expected value.
| Unfair | Non-Unfair | |
| Observed Engagements | 51.9277108433735 | 76.11592817679559 |
| Expected Engagements | 37.04196103238867 | 37.04196103238867 |
Table 2. Contingency table of manually-tagged topics on their engagement.
The process for testing the distribution of engagements for both manually-labeled topics followed the same process as with the first hypothesis test. However, instead of answering the hypothesis question directly, we concoct a secondary, intermediary research question: “Did the posts labeled Unfair receive the most engagements?” The intermediary null hypothesis is then: “Posts labeled Unfair received the most engagements,” with its negation as its corresponding alternative hypothesis.
The need to introduce an intermediary hypothesis is due to frequency and engagements being different metrics, and thus, cannot be directly compared to each other. Additionally, testing for the latter with no interventions requires prior testing of the former. This strategy ensures that no dependencies exist between the hypotheses for each research question, and in turn, minimizes the errors that come from this dependency conflict.
For a test of significance at α = 0.05 and df = 1, we get X2 = 4.5693 and p-value = 0.0325. This tells us that posts labeled Unfair did not receive the most engagements. Therefore, we reject the intermediary null hypothesis.
Given this data, we compare the data of the first research hypothesis testing. Since there are only two manually labeled topics, there are only two options as to which topic can have the most engagement. Since the Unfair topic was found to not receive the most engagement, then the most engaged topic must be the Non-Unfair topic, which, as seen in the first hypothesis testing, was found to be the most prevalent. As such, the most prevalent topic also received the most engagement, which in turn means that we fail to reject the actual null hypothesis.
PART III
Machine Learning Modeling
As discussed in the last part, we want to use machine learning models to further our investigation as it provides a more flexible and objective way to identify clusters, which is very crucial! Specifically, we will be using unsupervised learning since we want to interpret the differences and similarities among datapoints.
Latent Dirichlet Allocation
Continuing its introduction early on, LDA was chosen for topic extraction due to its effectiveness in uncovering hidden topics within large textual datasets. It is well-suited for this problem as it probabilistically assigns words to topics, allowing for the discovery of distinct and coherent themes within the subreddit discussions. For an in-depth explanation, we recommend reading this.
So far, we've already seen the topics extracted by LDA. But how can we visualize how far or different each topics are among each other? Enter t-SNE.
t-distributed Stochastic Neighbor Embedding (t-SNE)
t-SNE is a nonlinear dimensionality reduction (or manifold learning) ML algorithm that is good at reducing high-dimensional data to a lower-dimensional space (as the algorithm suggests). This makes it easier to visualize and cluster complex relationships among topics! For an in-depth explanation, we recommend reading this.
Hence, the combination of LDA for topic extraction and t-SNE for visualization by clustering these topics provides a comprehensive understanding of the key issues discussed by Filipino workers on r/AntiworkPH.
LDA and t-SNE Plot
Using scikit-learn's t-SNE, we then generate the plot shown in Figure 9. Each color represents a topic cluster, which are made up of points that each correspond to a post; the larger the radius of the point, the greater the engagement a post has accumulated.

Figure 9. t-SNE Clustering of LDA topics in the subreddit r/AntiworkPH.
Looking at the plot, we can see that the 3rd topic, identified as Job Application and the focus of our hypothesis, lagged as third in both the number of posts and engagements. The 2nd topic, identified as BPO Work & Culture, placed first for the total number of engagements, while the 5th topic, identified as Employee Well-being, placed first for the total number of posts. The 1st topic, identified as Employee Exit Process, placed last for both categories.
Moreover, we can see how each topic is grouped and how close they are. For instance, Workplace Management is relatively separate from Employee Exit Process, which could mean employees quit for reasons other than workplace management. BPO Work & Culture is closely related to Workplace Management and Job Application but relatively isolated from the others. This may be because BPO is a leading industry especially in the Philippines. Job Application dabbles with the others but ties closely with Employee Exit Process since an exit from a job usually means applying for another one. Employee Well-being interacts with all other clusters and has a small patch in the middle of the plot, which could indicate that it is a core concern of most posts.
PART V
Results & Conclusion
What are the prevalent topics about labor struggles submitted on r/AntiworkPH?
MANUAL TOPIC LABELING
•
The prevalent topic in the subreddit is not centered around unfair contracts and job offers.
•
Non-Unfair had the most posts consistently.
ML TOPIC MODELING
•
BPO Work & Culture had the most posts until Nov 2023.
•
Employee Exit Process took first place but has declined since we scraped our data.
Which of these topics receive the most Reddit engagements?
MANUAL TOPIC LABELING
•
The prevalent topic in the subreddit (i.e. Non-Unfair) received the most engagements.
•
Non-Unfair had the most engagement consistently.
ML TOPIC MODELING
•
BPO Work & Culture also had the most engagement until Nov 2023.
•
Employee Well-being took first place after, different from the topic with the most posts.
•
Topic with the most posts almost always has the most engagement, too.
Limitations/Recommendations
One limitation of the study was that a significant amount of collected posts contained other media like photos and videos with no text caption. While processing these submissions to translate the text inside these media was possible, we faced time constraints which led to only a small percentage being transcribed. In further, similar studies, we recommend that media-only submissions be transcribed so a more encompassing analysis would be achieved. Moreover, translating the data from Filipino to English to suit the ML models causes loss of meaning and context, so developing a model that is trained on Filipino language in investigating Philippine data would be highly beneficial.
Another limitation noted was that the subreddit of interest r/AntiworkPH, is fairly new, having started in 2022. During these times, the number of posts and the rate of posting were limited, leading to an implication that the current analysis is unrepresentative of users’ past grievances from before the start of the subreddit. Additionally, it is completely limited to the sentiments of the subreddit users despite many other Philippine subreddits existing on the platform dedicated to job-related topics. Broadening the scope of interest by including these related subreddits would be beneficial in providing a more well-rounded analysis, and would help solve the limitation of the study about the volume of posts in r/AntiworkPH in its early establishment.
Now, it's your turn
Our study proposed to highlight the most negative aspects of the Philippine Job Market and inform people what to expect and what should be changed from the current system. By shedding light on the common Filipino’s experiences and grievances, we can create a better working environment for future Filipino workers and advocate for better working regulations from the government.
Policymakers must lead the way by creating supportive and fair labor laws, streamlining the exit process, and implementing standards for effective management practices. Corporate leaders, particularly in the BPO sector, should prioritize employee well-being by introducing initiatives to mitigate night shift stress, fostering inclusive workplace cultures, and offering professional development and mental health support.
By taking these informed, data-driven actions, stakeholders can collectively create a more equitable and supportive work environment in the Philippines. Let us use these insights to drive positive change and empower Filipino workers.
There's so much data on the Internet—what will you do?




Meet the Team
_ |\_
\` ..\
__,.-" =__Y=
." )
_ / , \/\_
((____| )_-\ \_-`
`-----'`-----` `--`
Seth Eliserio
@setheliserioI am Eli, a BS Computer Science student, and my main field of interest is automata theory. I also enjoy exploring finance and some Taylor Swift on the side.
|\ _,,,---,,_
ZZZzz /,`.-'`' -. ;-;;,_
|,4- ) )-,_. ,\ ( `'-'
'---''(_/--' `-'\_)
Arki Mañago
@ark1techHi, I'm Arki. I love putting beauty to the things I build. My passion lies in fusing my marketing and programming skills. I love jogging and the flowers around UPD!‧₊˚❀༉‧₊˚.
_ |\'/-..--. / _ _ , ; `~=`Y'~_<._./ <`-....__.'
Annika Domondon
@maridapottedcatHello! I am Annika, a BS Computer Science student, currently interested in the marriages of computer science to other subjects, mainly bioinformatics. I also enjoy writing and discussing stories and literary concepts.